
6. 데이터베이스 생성과 삭제
DB생성 - CREATE DATEBASE DB명
DB삭제 - DROP DATEBASE DB명
테이블 생성 - CREATE TABLE TABLE명
테이블 삭제 - DROP TABLE TABLE명
DB, TABLE 명은 절대 한글 사용하면 안된다.
식별자로 사용하기 절대 X, 한글이 쓰인 사례는 대부분 이해를 돕기 위한 교육용이다.
1. 시작
1) SUNGJUK 테이블을 삭제해라
DROP TABLE SUNGJUK;

지난 번에 생성했던 SUNGJUK 테이블을 삭제하였다.
2. 시퀀스
교재 - CHAPTER 12 시퀀스와 뷰 참조
시퀀스란?
데이터베이스 객체로, 시퀀스 생성시 설정 규칙에 따라 정수를 반환한다.
오라클에서 자동으로 일련번호를 부여하는 것을 말한다.
기술방법 (옵션)
INCREMENT BY 증가값
START WIHT 시작값
MAXVALUE 최댓값
MINVALUE 최솟값
CYCLE 반복횟수
CHACHE
ORDER
시퀀스를 생성할때 - CREATE SEQUENCE SEQUENCE명;
INCREMENT BY 증가값
START WIHT 시작값
시퀀스에서 일련번호 발생
SEQUENCE명.NEXTVAL
시퀀스를 삭제할때 - DROP SEQUENCE SEQUENCE명;
1) SUNGJUK 테이블에서 사용할 시퀀스를 생성하기
CREATE SEQUENCE SUNGJUK;

SUNGJUK 시퀀스가 생성되었다.
DROP SEQUENCE SUNGJUK;

SUNGJUK 시퀀스가 삭제되었다.
시퀀스명은 주로 TABLE명_SEQ 로 짓는다.

그전에 예제로 만들었던 테이블은 식별해줄 수 있는 유일성을 가진 것이 없었다.
그래서 나쁜 설계였다.
테이블 설계할때 유일성을 보장하는 칼럼을 반드시 하나는 포함되어야한다.
2) SUNGJUK 테이블 다시 만들기
CREATE TABLE SUNGJUK(
SNO NUMBER NOT NULL --일련번호
,UNAME VARCHAR2(255) --이름
,KOR NUMBER NOT NULL --국어
,ENG NUMBER NOT NULL --영어
,MAT NUMBER NOT NULL --수학
,AVG NUMBER --평균
,ADDR VARCHAR2(255) --주소
,WDATE DATE --작성일
);

새로운 SUNGJUK 테이블을 생성하였다.
데이터베이스 모델링을 잘 해야한다. 설계는 자바에서 X , DB에서 잘 설계해놓고 불러오기
3) SUNGJUK 테이블에 행추가 하기
INSERT INTO SUNGJUK(SNO,UNAME,KOR,ENG,MAT,ADDR,WDATE)
VALUES(SUNGJUK_SEQ.NEXTVAL
,'임시완'
,100,95,80,'SEOUL',SYSDATE); --SEQ.NEXTVAL 시퀀스에서 번호를 알아서 매겨준다, SYSDATE 시스템날짜를 가져온다.

1 행 추가가 완료되었다.


이어서 9행을 더 추가하였다.
연습문제
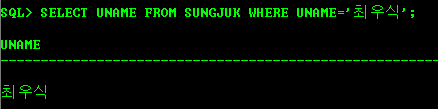
1) 이름 '최우식'를 조회하시오
SELECT UNAME FROM SUNGJUK WHERE UNAME='최우식';
2) 국어점수 50이하 조회하시오
SELECT UNAME,KOR FROM SUNGJUK WHERE KOR<=50;

3) 국영수 모두 90점 이상 조회하시오
SELECT UNAME,KOR,ENG,MAT FROM SUNGJUK WHERE KOR>=90 AND ENG>=90 AND MAT>=90;

4) 이름 송강호, 이보영, 현우진을 조회하시오
SELECT UNAME FROM SUNGJUK WHERE UNAME IN ('송강호','이보영','현우진');
SELECT UNAME FROM SUNGJUK WHERE UNAME = '송강호' OR '이보영' OR '현우진';

5) 주소가 서울인 레코드의 평균을 구하시오
UPDATE SUNGJUK SET AVG=(KOR+ENG+MAT)/3 WHERE ADDR = 'SEOUL';

6) 수학점수 50~59사이 레코드를 조회하시오
SELECT UNAME,MAT FROM SUNGJUK WHERE MAT BETWEEN 50 AND 59;

7) 비어있는 평균값을 모두 구하시오

아까 추가된 '임시완' 외 9행의 AVG정보가 추가되었다.
8) 평균 70점이상 레코드를 이름순으로 정렬해서 조회하시오
SELECT UNAME,AVG FROM SUNGJUK WHERE AVG>=70 ORDER BY UNAME ASC;

정렬은 데이터값을 깔끔하게 다 입력,설계하고 정리하는 것.
ex)게시판테이블에서 가장 최근에 작성한 글 순서로 출력
order by wdata desc --가장 최근 글 나옴.
※ 칼럼 보기좋게 정리한 명령어
COL UNAME FOR A8;
COL ADDR FOR A6;
SELECT * FROM SUNGJUK;
한 결과이다.

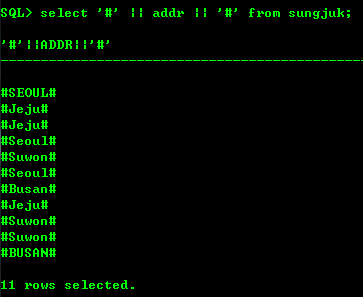
--연결문자 ||
--MySQL -> concat() 함수
SELECT '#' || ADDR || '#' FROM SUNGJUK;
9) AVG 칼럼의 데이터타입 NUMBER(6,2)으로 수정하시오
ALTER TABLE SUNGJUK MODIFY(AVG NUMBER(6,2));

이런 에러가 뜬다???
데이터값이 존재했을때 데이터타입 변경이 불가하기 때문이다.
UPDATE SUNGJUK SET AVG = NULL;
ALTER TABLE SUNGJUK MODIFY(AVG NUMBER(6,2));
UPDATE SUNGJUK SET AVG = (KOR+ENG+MAT)/3;
DESC SUNGJUK;

ADDR의 타입이 변화한 것을 확인할 수 있다.
10) 수학점수 50점 미만 학생들에게 수학점수 5점씩 추가하시오
UPDATE SUNGJUK SET MAT = MAT+5 WHERE MAT<50;

수학점수 50점 미만이었던 최우식, 이우환, 송강호의 점수가 5점씩 올랐다.
11) 이름에 '우' 문자가 들어가 있는 레코드만 검색
SELECT UNAME FROM SUNGJUK WHERE UNAME LIKE '%우%';

12) 주소가 'Seoul','Jeju'이면서 이름에 성이 '최'인 레코드 조회
SELECT UNAME,ADDR FROM SUNGJUK WHERE UNAME LIKE '최%' AND ADDR IN ('SEOUL','JEJU');

13) 국영수 과목의 각 평균을 구하시오
UPDATE SUNGJUK SET AVG = (KOR+ENG+MAT)/3;

문제를 잘못이해했다.
SELECT AVG(KOR) AS AVG_KOR, AVG(ENG) AS AVG_ENG, AVG(MAT) AS AVG_MAT FROM SUNGJUK;

각 과목의 평균을 말한 것이었다.
14) 국영수 과목의 각 평균을 반올림해서 소수점 두자리까지 출력하시오
SELECT ROUND(AVG(KOR),2) AS AVG_KOR ,ROUND(AVG(ENG),2) AS AVG_ENG ,ROUND(AVG(MAT),2) AS AVG_MAT FROM SUNGJUK;

3. DB의 자료형
DB에서 자료형 표준안이 있다.
[ORACLE DB의 자료형]
1) 숫자형
NUMBER (INT라고 써도 DB내에서 알아서 NUMBER로 인식)
INT - 표준
NUMBER 정수형
NUMBER(5,2) 실수형 (999, 99)
2) 문자형
CHAR 고정형, 표준
-> CHAR(5)
-> 'SKY ' 고정이라 빈 공백 그대로
-> 우편번호
아예 정해놓은 것이기 때문에 고정형이 더 빠르다.
VARCHAR 가변형, 표준
-> VARCHAR(5)
-> 'SKY ' 빈 공백 없앰
-> 아이디, 비번, 이름, 주소~~
VARCHAR2 가변형 (ORACLE의 표준)
3) 날짜형 (년월일시분초)
DATE
SYSDATE : 현재 시스템 날짜 함수
TIMESTAMP
INTERVAL
4. Oracle에서 자주 쓰이는 함수DB의 자료형
DB에서 자료
1. 집계 함수
max(column) - 최대값을 구하는 함수 ex) select max(sal) from emp => 1600
min(column) - 최소값을 구하는 함수 ex) select min(sal) from emp => 800
avg(column) - 평균값을 구하는 함수 ex) select avg(sal) frop emp => 1200
sum(column) - 합계를 구하는 함수 ex) select sum(sal) from emp => 3600
count(*) - 총 레코드 수를 세는 함수, null값도 포함 ex) select count(*) from emp => 3
count(컬럼명) - 컬럼명을 기준으로 총 레코드 수를 세는 함수, null값은 제외 ex) select count(comm) from emp =>2
2. 문자열 함수
lower('Hello World') - hello world, 해당 컬럼의 값을 소문자로 변환하는 함수
upper('Hello World') - HELLO WORLD, 해당 컬럼의 값을 대문자로 변환하는 함수
inicap('go go go!') - Go Go Go!, 첫글자와 공백이후 첫글자는 대문자로 변환하는 함수
concat('Helllo', 'World') - Hello World, 두 개의 문자열을 연결하는 함수
substr('HelloWorld', 6) - World, 문자열의 6번째자리부터 전체를 추출
substr('HelloWorld', 1, 5) - Hello, 문자열의 1번째자리부터 5자까지 추출하는 함수
length('oracle') - 6, 문자열의 총 길이를 세는 함수
instr('HelloWorld', 'W') - 6, 문자열에서 특정문자의 위치를 세는 함수,만약 특정문자가 문자열에 없다면 0 반환
lpad('SQLPLUS', 10, '*') - ***SQLPLUS, 우측부터 해당길이에 부족한 부분은 특정문자로 채우는 함수
rpad('SQLPLUS', 10, '*') - SQLPLUS***, 좌측부터 해당길이에 부족한 부분은 특정문자로 채우는 함수
trim(' SQLPLUS') - SQLPLUS, 공백을 제거하는 함수
ltrim('*SQLPLUS', '*') - SQLPLUS, 좌측부터 문자열에서 해당 문자를 제거하는 함수
rtrim('SQLPLUS*', '*') - SQLPLUS, 우측부터 문자열에서 해당 문자를 제거하는 함수
replace('SEVLTL', 'L', 'EN') - SEVENTEN, 문자열에서 해당 문자를 다른 문자로 바꾸어주는 함수
nvl(expr1, expr2) - expr1이 null이면 expr2 값으로 반환하는 함수
nvl2(expr1, expr2, expr3) - expr1과 null1을 비교해 null이 아니면 expr2, null이면 expr3을 반환하는 함수
nullif(expr1, expr2) - expr1과 expr2를 비교하여 같으면 null, 다르면 expr1을 반환하는 함수
coalesce(expr1, expr2, ... exprn) - expr1~exprn 목록에서 첫번째로 null이 아닌 expr을 반환
3. 숫자 함수
abs(-7) - 7, 절대값을 계산하는 함수
mod(1500, 200) - 100, 1500 / 200 의 나머지를 반환하는 함수
ceil(1.123) - 2
ceil(-1.623) - -1, 소수점 첫째자리에서 해당 값을 올림 처리한 정수를 반환하고 해당 값보다는 크지만 가장 근접하는 최소값을 구하는 함수
floor(1.123) - 1
floor(-1.123) - -2, 소수점 첫째자리에서 해당 값을 내림 처리한 정수를 반환하고 해당 값보다는 작지만 가장 근접하는 최대값을 구하는 함수
round(17.825, 2) - 17.86
round(17.825, 1) - 17.8
round(17.825, 0) - 18
round(17.825, -1) - 20
round(17.825,-2) - 0
round(n, m) - 해당 숫자n에m자리까지 반올림하는 함수
trunc(17.825, 2) - 17.82
trunc(17.825, 1) - 17.8
trunc(17.825, 0) - 17
trunc(17.825, -1) - 10
trunc(17.825, -2) - 0
trunc(n. m) - 해당 숫자 n에서 m자리까지 버림하는 함수
4. 날짜 함수
sysdate - 현재 날짜, 시간 ex) select sysdate from dual; - 14/03/24
months_between(sysdate, to_date('2014-12-11')) - -8.5659965,
months_between(to_date('2014-12-11'), sysdate) - 8.56597409, 첫번째 날짜에서 두번째 날짜 사이 개월 수를 반환하는 함수
add_months(sysdate, 5) - 14/08/24
add_months(sysdate, -5) - 13/10/24, 해당 날짜에서 개월 수를 더한 날짜를 반환하는 함수
next_day(sysdate, '금요일') - 14/03/28, 해당 날짜에서 최초로 도래하는 해당 요일의 날짜를 반환하는 함수
last_day(sysdate) - 14/03/31, 해당 날짜가 포함되어 있는 달의 마지막 날짜를 반환하는 함수
5. 형변환 함수
TO_CHAR(원래 날짜, '원하는 모양') - 숫자와 날짜를 문자로 변환해 주는 두가지 기능
TO_NUMBER('1')
TO_DATE('문자','날짜포맷')
연습문제 Ⅱ
아래 예제 테이블 보고 테이블설계 하고 값 넣어보기.

CREATE TABLE EMP (
EMPNO INT NOT NULL
,ENAME VARCHAR(10) NOT NULL
,JOB VARCHAR(10) NOT NULL
,MRG CHAR(4) NOT NULL
,HIREDATE DATE NOT NULL
,SAL INT NOT NULL
,COMM INT
,DEPTNO INT NOT NULL);
INSERT INTO EMP(EMPNO,ENAME,JOB,MRG,HIREDATE,SAL,DEPTNO)
VALUES (7369,'SMITH','CLERK','7902','1980-12-17',800,20);
INSERT INTO EMP(EMPNO,ENAME,JOB,MRG,HIREDATE,SAL,COMM,DEPTNO)
VALUES (7499,'ALLEN','SALESMAN','7698','1981-02-20',1600,300,30);
INSERT INTO EMP(EMPNO,ENAME,JOB,MRG,HIREDATE,SAL,COMM,DEPTNO)
VALUES (7521,'WARD','SALESMAN','7698','1981-02-22',1200,500,30);
COL ENAME FOR A8;
COL JOB FOR A8;
SELECT * FROM EMP;

'Backend' 카테고리의 다른 글
| 06월 25일 수 | SW활용 08 - MySQL과 DB연습Ⅱ (0) | 2019.06.26 |
|---|---|
| 06월 25일 화 | SW활용 07 - NCS 시험범위와 DB연습Ⅰ (0) | 2019.06.25 |
| 06월 21일 금 | SW활용 05 - 데이버베이스 연동하기 (0) | 2019.06.21 |
| 06월 20일 목 | SW활용 04 - SQL 데이터타입과 테이블설계 (0) | 2019.06.20 |
| 06월 19일 수 | SW활용 03 - 데이버베이스 설계와 DB서버 (0) | 2019.06.19 |




댓글